

Artemka2012
Премиум
- Регистрация
- 11 Апр 2015
- Сообщения
- 141
- Реакции
- 496
- Тема Автор Вы автор данного материала? |
- #41
Сборник рецептов #26: мобильные версии сайтов, список регионов Яндекса и упоминания домена в индексе
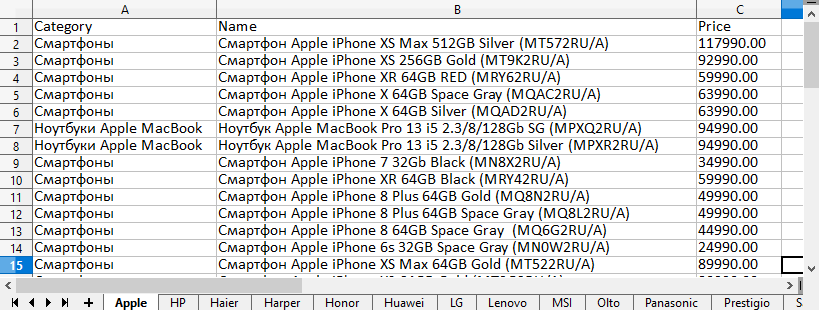
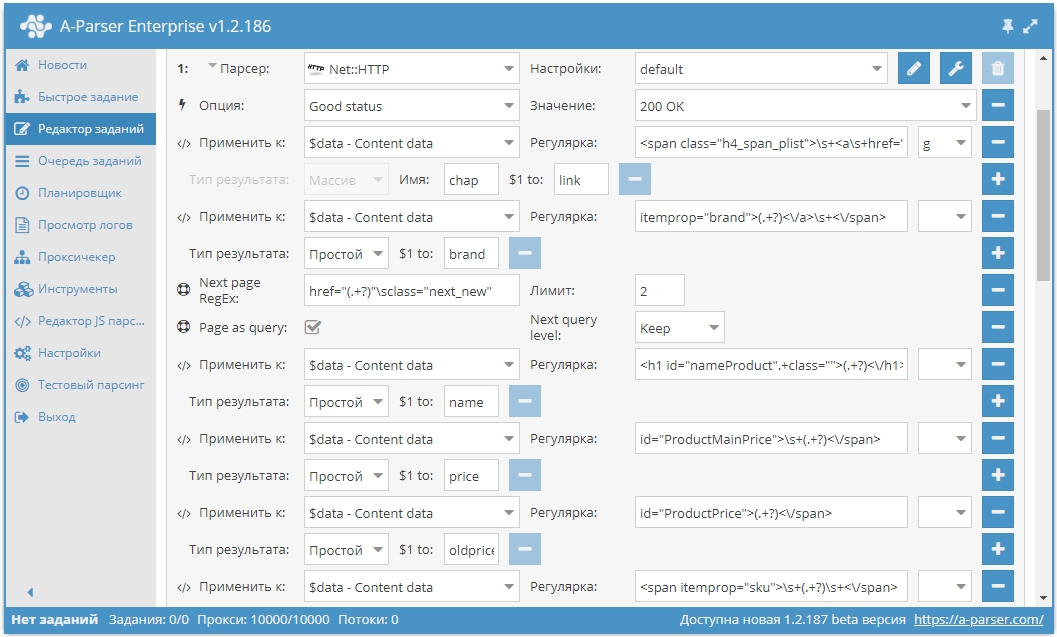
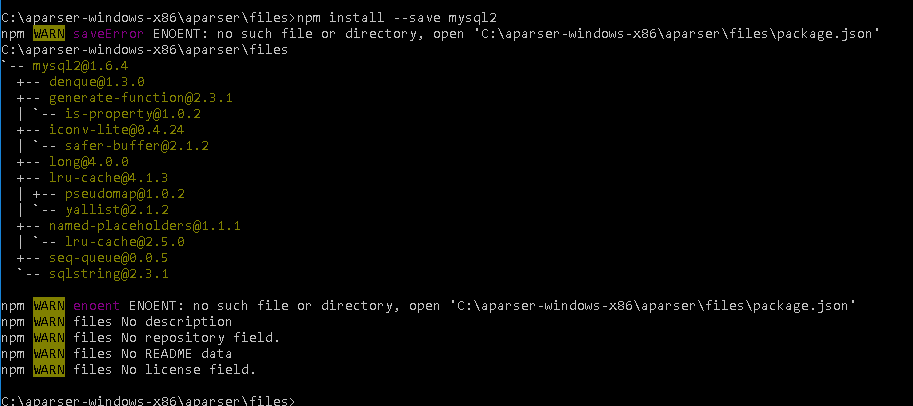
26-й сборник рецептов. В нем будут показаны: проверка наличия мобильной версии сайта через Bing, парсинг полного списка регионов Яндекса и способ поиска упоминаний домена в индексе поисковой системы. Также показан пример работы с Node.js модулем mysql2, который позволяет работать с MySQL базами данных. Поехали!
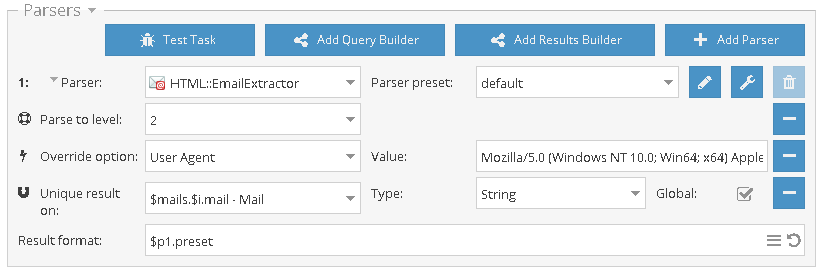
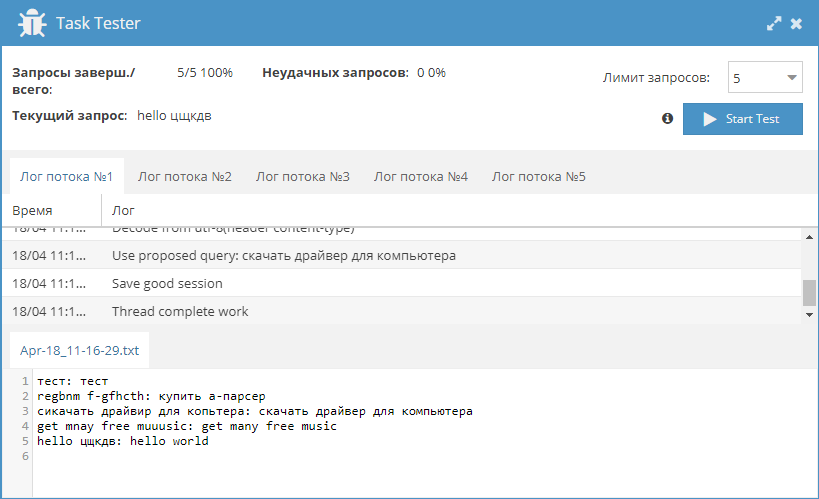
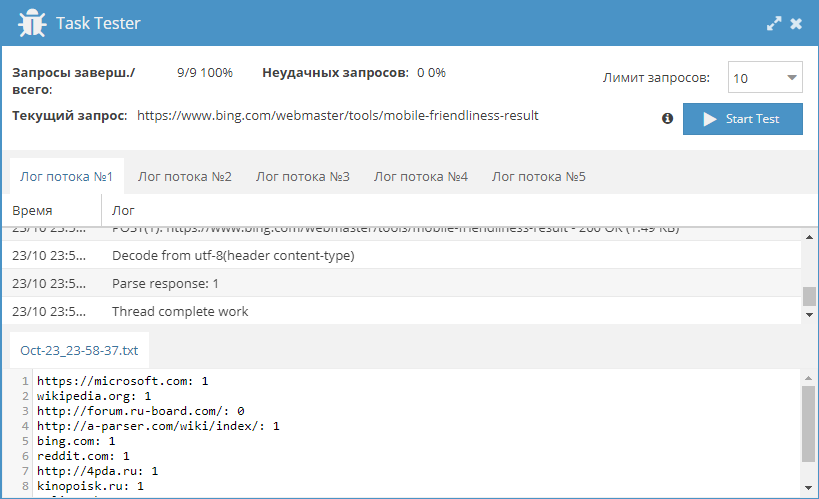
Проверка наличия мобильной версии через Bing
На сегодняшний день наличие мобильной версии является одним из важнейших критериев качества сайта. По данным различных организаций доля мобильного трафика уже давно превышает десктопный. Именно поэтому мобильная версия сайта позволяет увеличить посещаемость сайта, ведь большинство крупных поисковиков отдают предпочтение в выдаче сайтам, имеющим полноценную мобильную версию. Проверить наличие и соответствие стандартам можно с помощью небольшого пресета по ссылке выше.
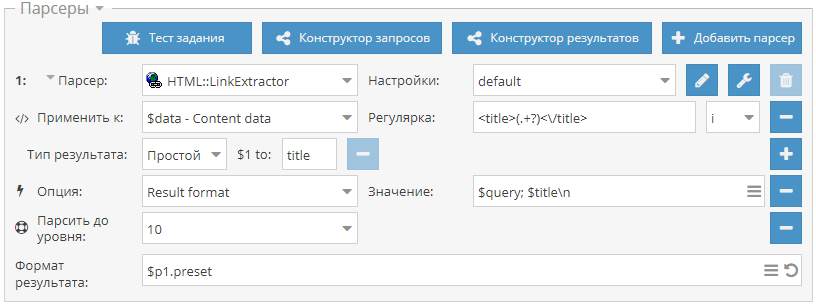
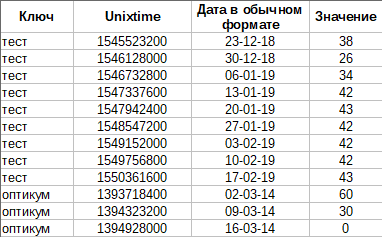
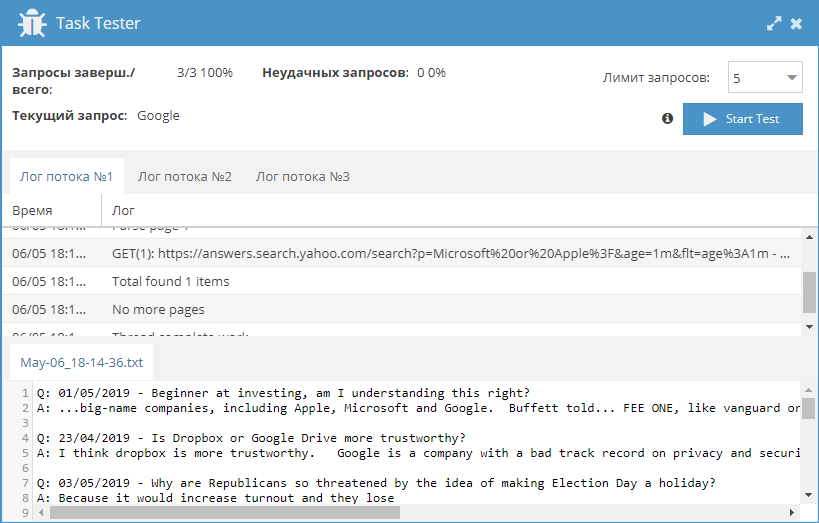
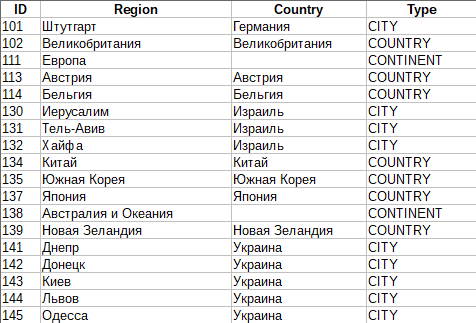
Получение полного списка регионов Яндекса
Яндекс не публикует в открытом виде полного списка всех регионов, используемых в поиске. И как оказалось, найти полную и актуальную базу в интернете практически невозможно. Поэтому мы исправляем это и по ссылке выше публикуем JavaScript парсер, который позволяет собрать свежую и максимально полную базу регионов Яндекса.
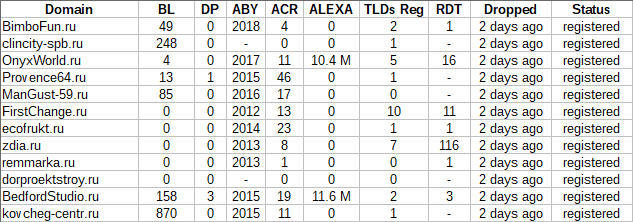
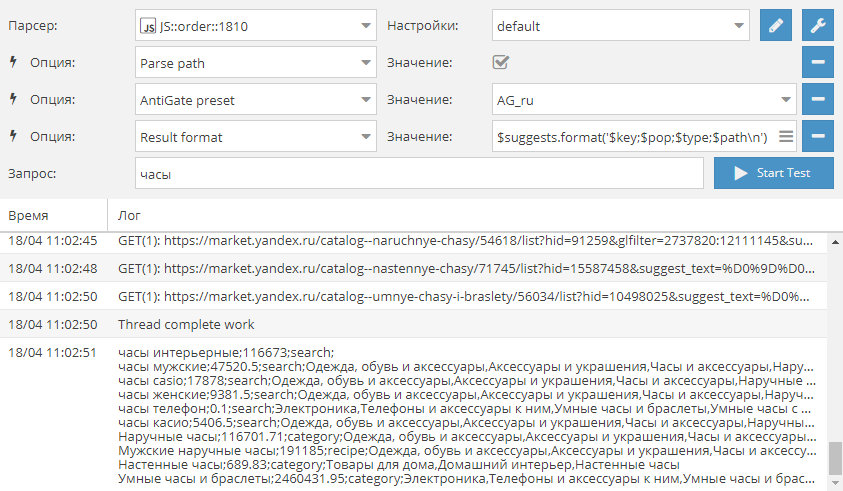
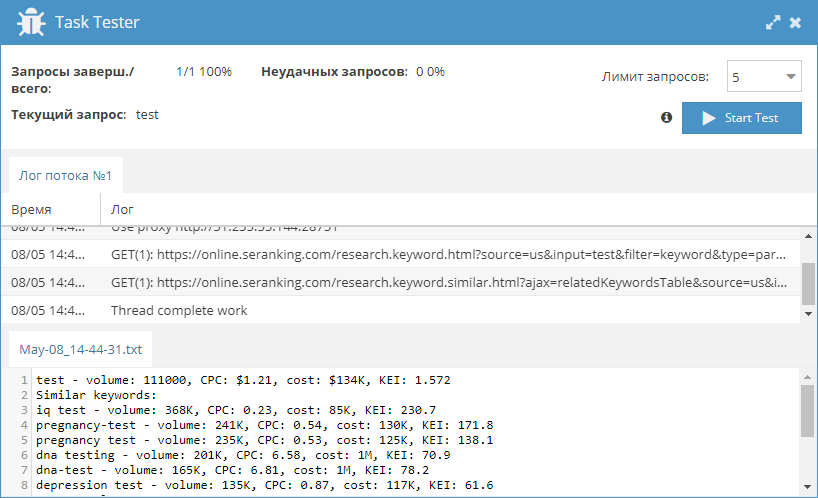
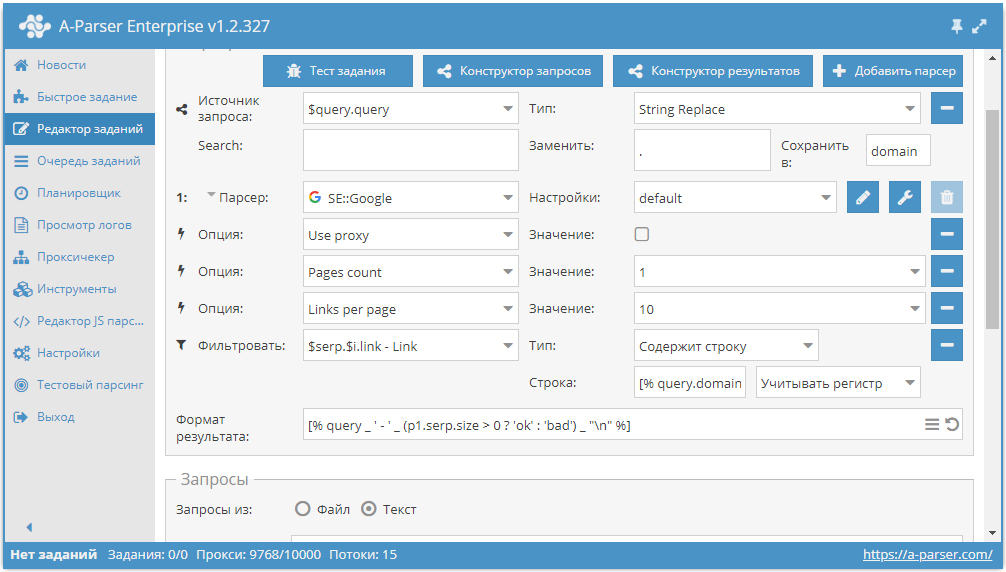
Проверка упоминаний домена в индексе Гугла
Иногда возникает задача по поиску упоминаний домена в индексе поисковой системы. Именно с такой задачей к нам обратился один из пользователей A-Parser. Поэтому по ссылке выше мы публикуем пресет, решающий данную задачу.
Кроме этого:
Еще больше различных рецептов в нашем Каталоге!
Предлагайте ваши идеи для новых парсеров здесь, лучшие будут реализованы и опубликованы.
Подписывайтесь на наш канал на Youtube - там регулярно выкладываются видео с примерами использования A-Parser, а также следите за новостями в Twitter.
26-й сборник рецептов. В нем будут показаны: проверка наличия мобильной версии сайта через Bing, парсинг полного списка регионов Яндекса и способ поиска упоминаний домена в индексе поисковой системы. Также показан пример работы с Node.js модулем mysql2, который позволяет работать с MySQL базами данных. Поехали!
Проверка наличия мобильной версии через Bing
На сегодняшний день наличие мобильной версии является одним из важнейших критериев качества сайта. По данным различных организаций доля мобильного трафика уже давно превышает десктопный. Именно поэтому мобильная версия сайта позволяет увеличить посещаемость сайта, ведь большинство крупных поисковиков отдают предпочтение в выдаче сайтам, имеющим полноценную мобильную версию. Проверить наличие и соответствие стандартам можно с помощью небольшого пресета по ссылке выше.
Получение полного списка регионов Яндекса
Яндекс не публикует в открытом виде полного списка всех регионов, используемых в поиске. И как оказалось, найти полную и актуальную базу в интернете практически невозможно. Поэтому мы исправляем это и по ссылке выше публикуем JavaScript парсер, который позволяет собрать свежую и максимально полную базу регионов Яндекса.
Проверка упоминаний домена в индексе Гугла
Иногда возникает задача по поиску упоминаний домена в индексе поисковой системы. Именно с такой задачей к нам обратился один из пользователей A-Parser. Поэтому по ссылке выше мы публикуем пресет, решающий данную задачу.
Кроме этого:
Еще больше различных рецептов в нашем Каталоге!
Предлагайте ваши идеи для новых парсеров здесь, лучшие будут реализованы и опубликованы.
Подписывайтесь на наш канал на Youtube - там регулярно выкладываются видео с примерами использования A-Parser, а также следите за новостями в Twitter.
















") ) - отписывайтесь
) - отписывайтесь