

A-Parser support
Premium Lite
- Регистрация
- 24 Янв 2019
- Сообщения
- 133
- Реакции
- 16
Видео урок: Макросы подстановок
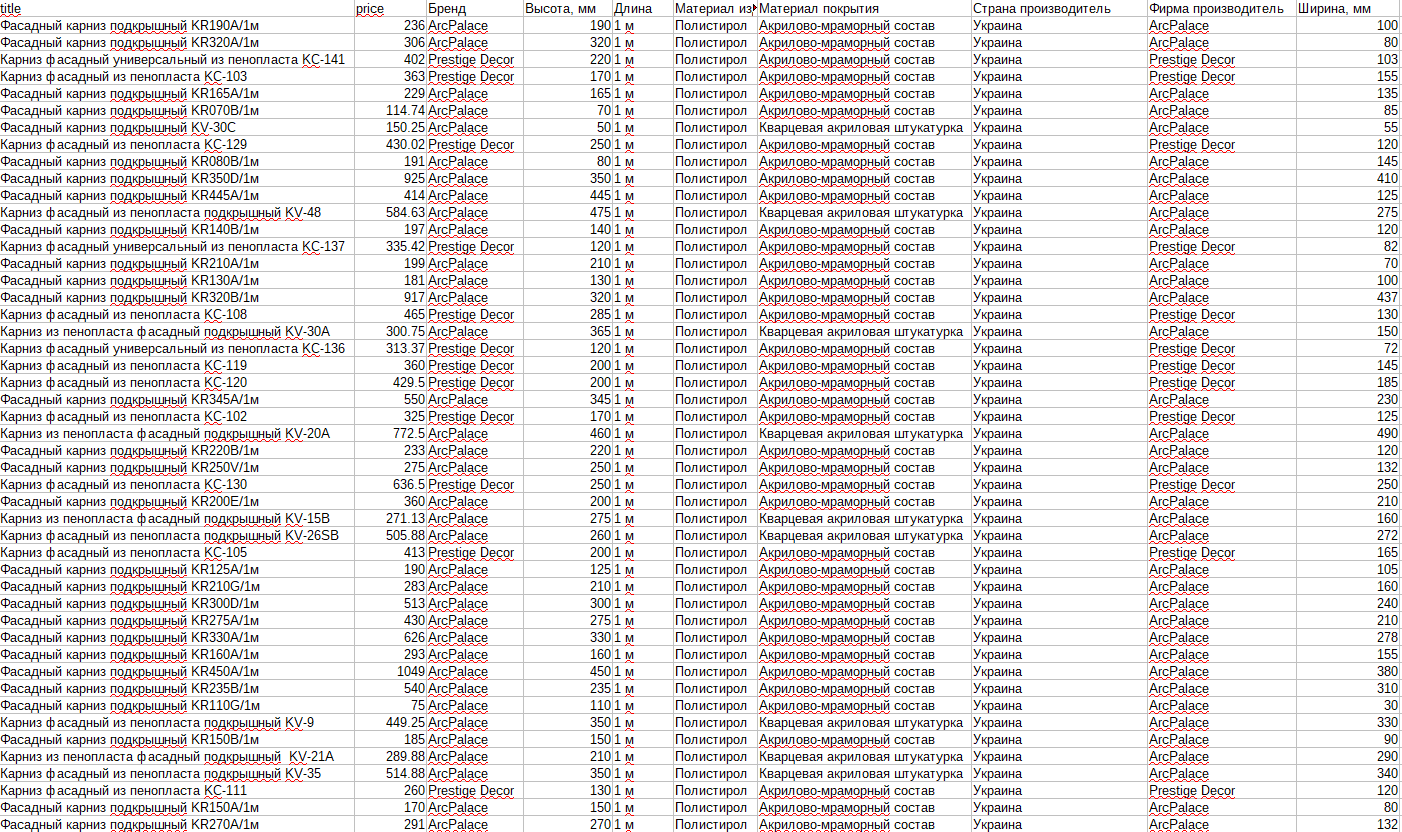
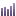
В этом видеоуроке мы изучим один из инструментов для работы с запросами - макросы подстановок. С их помощью можно значительно увеличивать количество запросов, листать страницы и многое другое.

В уроке рассмотрено:
Полезные ссылки:
Оставляйте комментарии и подписывайтесь на наш канал на YouTube!

В этом видеоуроке мы изучим один из инструментов для работы с запросами - макросы подстановок. С их помощью можно значительно увеличивать количество запросов, листать страницы и многое другое.
В уроке рассмотрено:
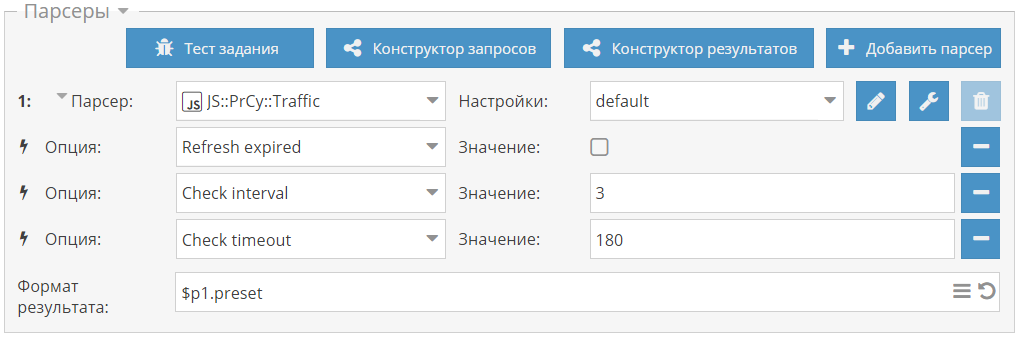
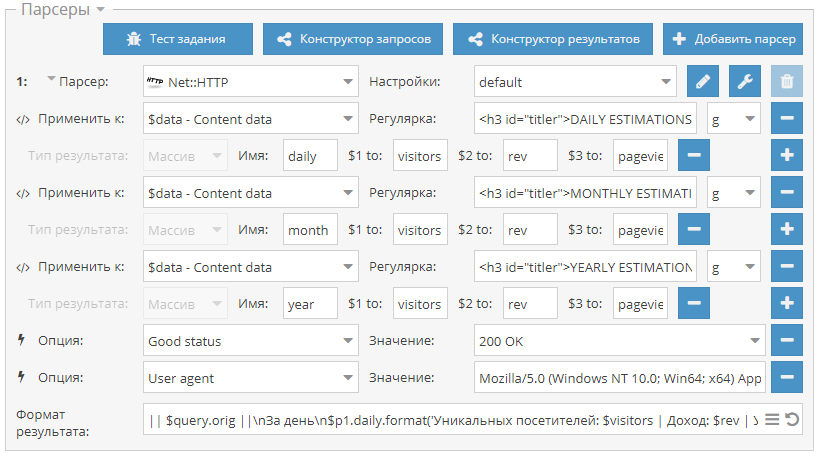
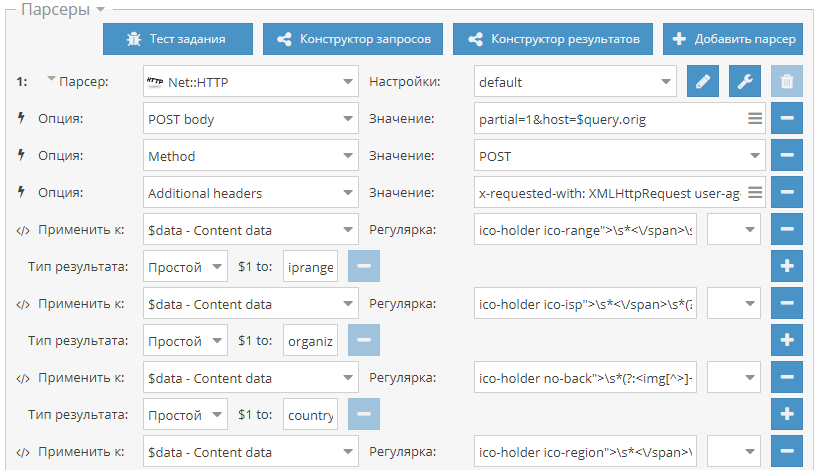
- макрос {num} на примерах прохода по страницам и перебора координат в парсере Google maps
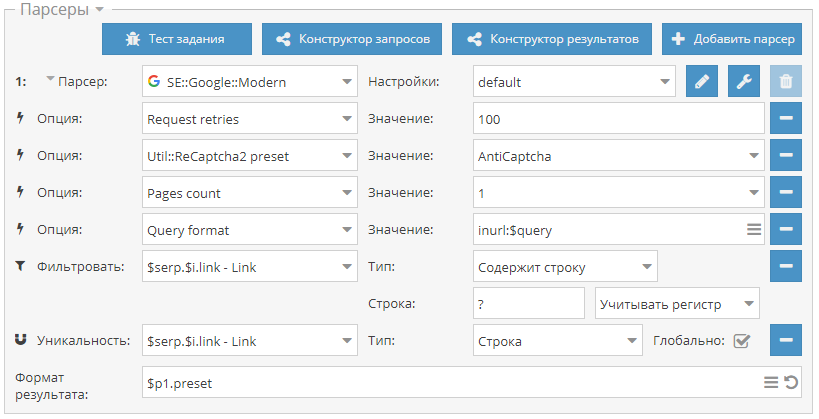
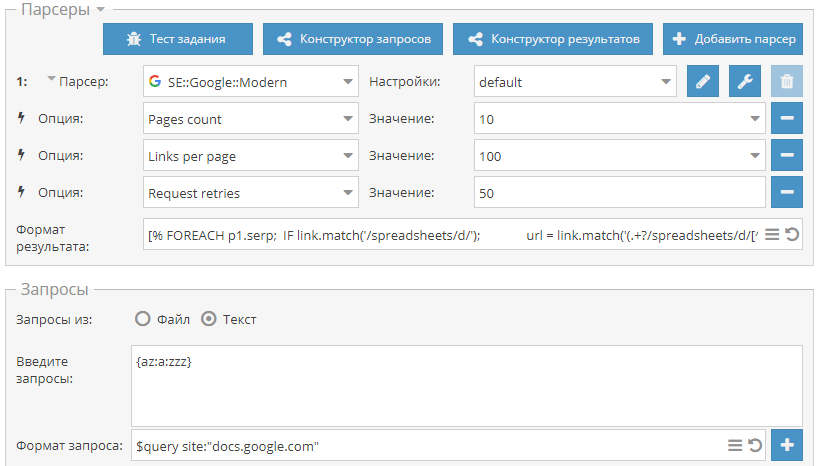
- макрос {az} на примере парсинга по доркам для увеличения кол-ва запросов и соответственно результатов
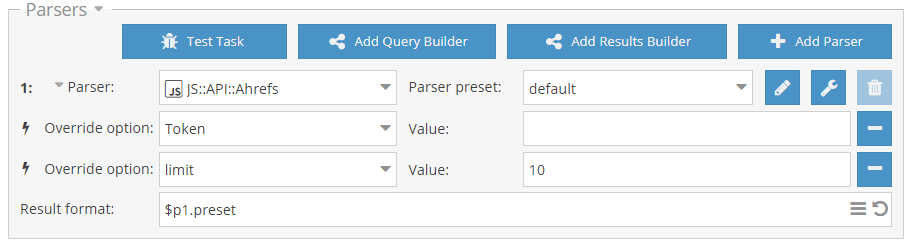
- макрос {each} на примере парсинга подсказок для генерации словосочетаний
Полезные ссылки:
- Форматирование и подстановки запросов | A-Parser - парсер для профессионалов SEO - документация по макросам подстановок
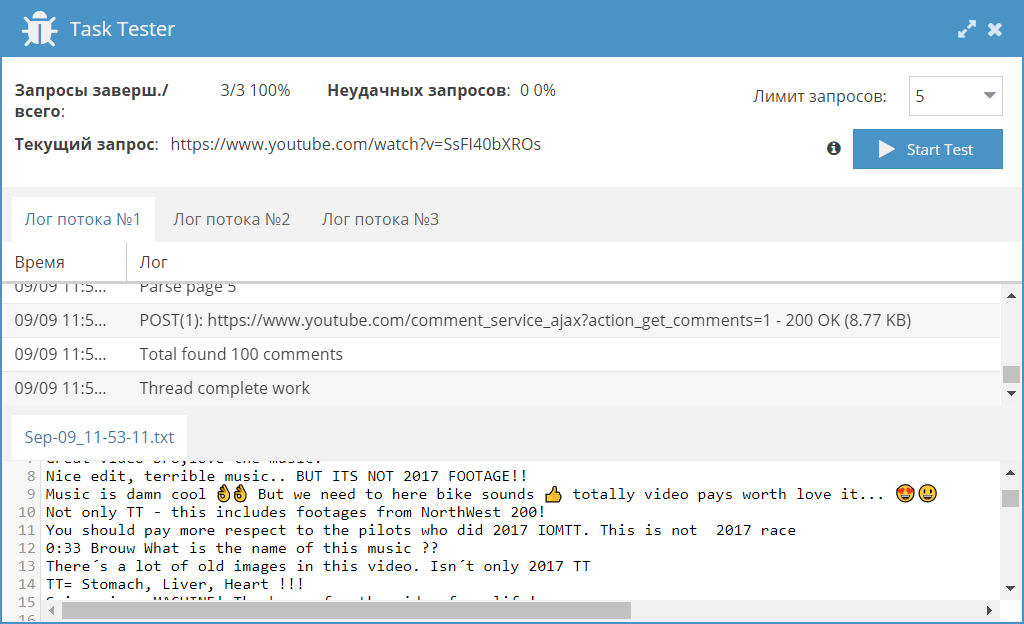
- Сбор всех организаций в определенной местности - пресет по перебору координат в
Maps::Google

- Проход по страницам с помощью макроса {num}
- Размножение запросов с помощью макроса {az} на примере парсинга с inurl: - пресет для парсинга с inurl:
- Генерация словосочетаний для запросов с помощью макроса {each} - пресет для парсинга подсказок
Оставляйте комментарии и подписывайтесь на наш канал на YouTube!


 ost
ost




















 Net::HTTP
Net::HTTP Util::ReCaptcha2
Util::ReCaptcha2 SE::Rambler
SE::Rambler Social::Instagram::Profile
Social::Instagram::Profile Social::Instagram::Tag
Social::Instagram::Tag